INSTANT ON NOW AVAILABLE - Experience Time to first frame as quick as 2 SECONDS
News & Updates
Understanding Deployment Options for Streaming Real-Time Experiences: On Demand vs Dedicated vs Hybrid

The perfect cloud-streaming platform for distributing metaverse experiences is one that is perfectly elastic, scalable, and precisely schedulable. Previously, those qualities were difficult to find in a single system. However, the new PureWeb Reality platform offers "Capacity Providers", so you don't have to compromise on those qualities.
Different Capacity Providers excel in different ways: For time-bound events with a large number of users, our Dedicated option lets you reserve server capacity ahead of time to deliver the best experience for your many end users. For ad-hoc, ongoing, or scenarios with a low number of expected concurrent users at any given time, our On Demand capacity is your best (and most cost-effective) choice.
It doesn't stop there. We also offer a Hybrid solution that might be ideal for your project - this scenario means you have provisioned some dedicated Scheduled infrastructure, while overflow requests will be served by our On Demand resources.
Let us break down the options further.
Dedicated
Dedicated capacity is a good fit when the usage patterns of an experience are known or predictable, there is a known time for availability, or a finite number / large capacity (100+ sessions) of infrastructure is needed.
There is some flexibility possible in a Dedicated environment through autoscaling features and cost is incurred for provisioned resources, regardless of whether they are providing active streams or not.
If your project is configured to use Dedicated capacity only, then requests will be routed to the nearest region that has dedicated capacity for models in that project.
On Demand
Our On Demand capacity leverages a shared pool of resources that can run any customer model. This reduces the burden of trying to predict usage patterns for your experience. Additionally, it allows you to run ad-hoc or ongoing experiences, because it removes the need to maintain a minimum amount of dedicated infrastructure to ensure your experience can be streamed.
If your project is configured to use On Demand capacity only, the system will route users to the closest region with an On Demand pool.
There are, however, a few caveats to note.
These resources differ in implementation from Dedicated. Each On Demand resource runs your model inside a container. A container is an isolated, lightweight environment that can only run a single process at a time, which means there are a few limitations:
- On Demand capacity only supports Unreal Engine packages (for now).
- Any model that requires an active Windows desktop, or full Windows Server OS, will not work in On Demand.
- Any model that tries to launch an external process or executable will not be able to do so inside the container environment.
Hybrid
In a hybrid scenario, your project is configured to use Dedicated capacity that will spill into On Demand capacity if necessary.
The system will route users to the nearest region that has Dedicated capacity first. If there is no scheduled capacity available, they will be routed to the On Demand provider in that region.
No autoscaling of the dedicated resources would occur in a hybrid deployment.
Currently requests will stay within predefined regions, to avoid high latency connections. For example, in a hybrid scenario, a request from North America would not be connected to a server in Asia or Europe; the request would always be fulfilled by resources within North America.
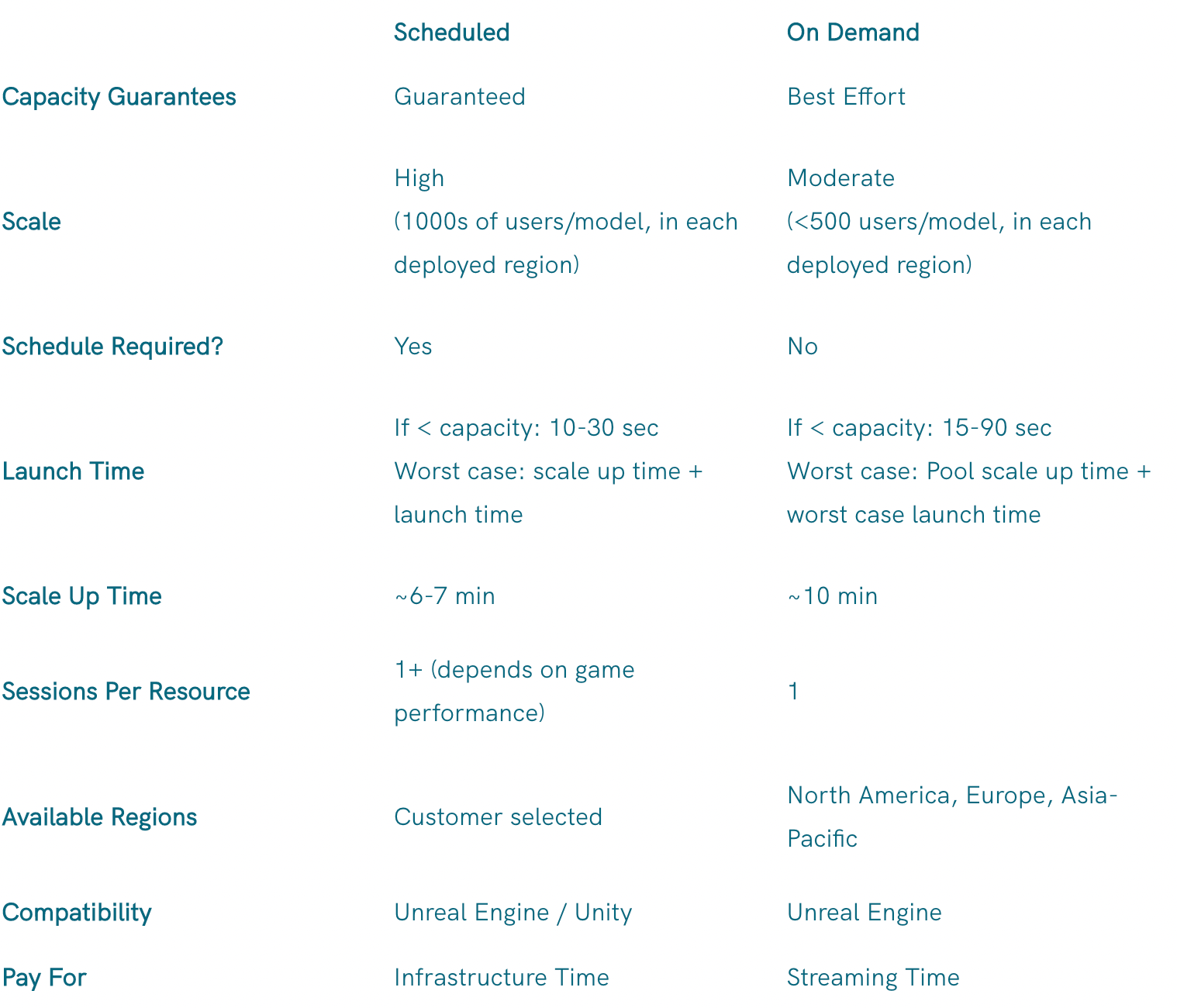
Below is an easy comparative chart to determine which option is ideal for your project.
Scheduled / Always Available Comparison
Of course, you can always contact us - we are happy to help you select the right option to support your needs.


